How to Save Tokens When Using AI Models
A practical explanation of why long AI chats get more expensive and less reliable, plus simple ways to keep context under control.
How token costs quietly grow in AI chats
Most AI chat apps feel like a running conversation. The screen shows one thread, previous replies stay visible, and the model often refers to earlier messages.
Under the hood, that is not what happens.
Large language models are stateless. On each new message, the app sends the relevant conversation history back to the model again. The model reads that input, generates a reply, and stops. No memory is carried from the previous call unless the software sends it back.
That detail matters for two reasons:
- Long chats cost more than they seem
- Long chats also tend to get worse over time
What "stateless" means
A simple way to think about it: each message is treated like a fresh request with a copy of earlier context attached.
That context can include:
- earlier messages
- system instructions
- uploaded files
- tool output
- code, logs, or pasted text
In a consumer chat app, most of that packaging happens automatically. In an API integration, the developer often manages it directly. Either way, the model usually sees a rebuilt prompt on every turn.
Some platforms now offer server-managed conversation state, but that mostly changes where the history is stored. It does not change the basic pricing model. Earlier context still counts.
Why the 💰 grows
A short chat is cheap because the history is still small.
A long chat is different. By the tenth or twentieth turn, the model may be rereading a large transcript every time. A message that looks short on screen can still trigger a large request because the hidden cost sits in the accumulated context.
That is why agent tools and coding assistants can get expensive fast. A session may include:
- file contents
- terminal output
- tool results
- intermediate plans
- repeated revisions
Every extra chunk increases the size of the next request.
The pattern is simple: each turn adds new tokens, and later turns pay again for much of what came before.
Why quality drops too
Cost is only half of the problem.
Long context also makes retrieval and reasoning harder. Research on long-context models has shown a consistent pattern: models perform better when relevant details are near the beginning or end of the context, and worse when those details are buried in the middle.
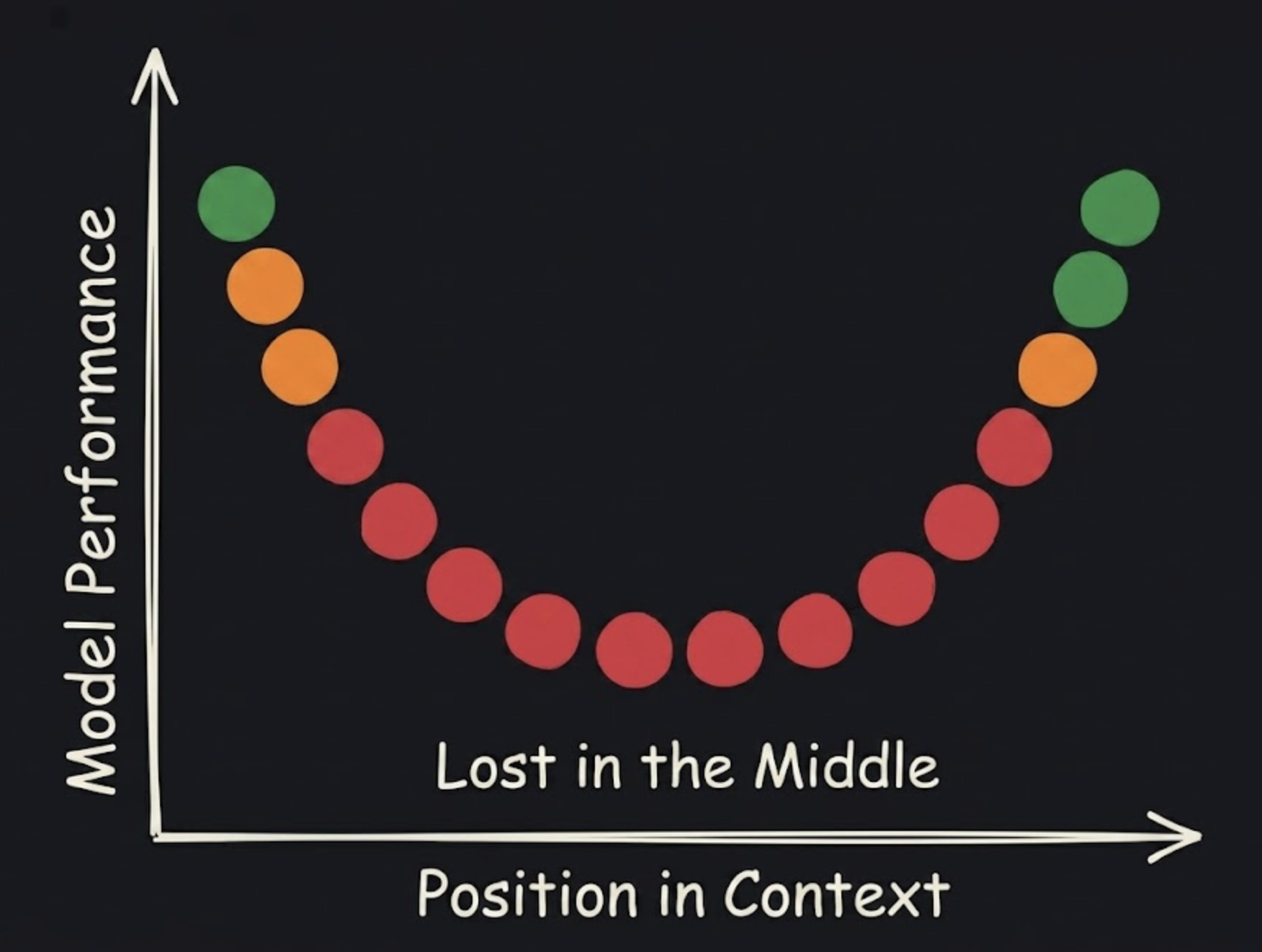
In practice, that often looks like this:
- an early requirement gets ignored
- a pasted log line is missed
- a model repeats an outdated assumption from twenty messages earlier
- a reply addresses the latest message but loses an important detail from the middle of the thread
This can happen even when the total input still fits within the advertised context window. "Fits" does not mean "uses every part equally well."
What saves tokens in practice
A few habits make a noticeable difference.
Start a new chat sooner
One thread per task usually works better than one giant thread for everything.
If the topic changes from debugging to writing, or from research to code review, a fresh chat is often cheaper and clearer than dragging old context forward.
Paste less
Large logs, long transcripts, and full files are expensive context.
Only the part needed for the current question belongs in the prompt. A small relevant excerpt is usually better than a full dump.
Restate the current goal
Important constraints should appear close to the current request.
A short reminder like "keep this beginner-friendly" or "only modify the API route" is often more effective than relying on something written much earlier in the thread.
Use summaries and compaction
Some tools provide context compaction or summarization. Those features exist for a reason. Replacing a long back-and-forth with a short summary reduces future token usage and often improves answer quality.
For manual workflows, a plain summary works too:
Current state:
- root cause identified in auth middleware
- failing path is refresh token rotation
- keep existing database schema
- next step is patch + test
That summary is cheaper and easier to use than twenty screens of mixed history.
Treat every message like a fresh prompt
This is the most useful mental model.
Instead of assuming the model "remembers," assume the next reply depends on whatever context is attached right now. That shift usually leads to shorter prompts, cleaner chats, and fewer surprising misses.
A simple technical example
Consider a debugging chat for a failing login flow.
The first part of the thread might include middleware code, API responses, database schema notes, stack traces, and several failed hypotheses. Twenty messages later, a small request like "patch the refresh token bug" may still carry all of that earlier context with it.
That means:
- more tokens billed for a narrow follow-up task
- more chances for the model to rely on stale logs or abandoned assumptions
A fresh chat with a short summary is usually better:
Bug summary:
- issue: refresh token rotation fails after login
- confirmed area: auth middleware
- do not change database schema
- next step: patch handler and add regression test
Same task, less baggage.
The useful rule
AI chats are not ongoing memory sessions. They are repeated requests with context attached.
Once that clicks, the practical advice becomes straightforward:
- keep threads smaller
- carry forward only what matters
- summarize often
- reset when the task changes
That approach saves tokens and usually produces better answers.
Sources
- Anthropic. Using the Messages API
- OpenAI. Managing conversation state
- Google. Gemini API interactions
- Anthropic. Prompt caching
- Google. Gemini API context caching
- Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the Middle: How Language Models Use Long Contexts
- Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What's the Real Context Size of Your Long-Context Language Models?
- Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Seunghyun Yoon, and Hinrich Schuetze. NoLiMa: Long-Context Evaluation Beyond Literal Matching
Related posts
- Building Personal AI Assistant with GitHub Copilot SDKMarch 14, 2026
- My Git + GitHub Workflow with Agent SkillsFebruary 15, 2026
- My Current Agentic Coding WorkflowFebruary 7, 2026